Visualize your massive data with Impala and Redash
Redash is a famous OSS visualization tool, which enables to visualize your data with SQL. It supports Apache Impala (incubating), fast SQL-on-Hadoop suitable for BI tools and exploratory analysis. With Impala, you can query SQLs to tables on Amazon S3.
In this post, we connect to Impala from Redash and visualize data.
Set up Redash
You can set up Redash with various way. This time, I use AMI for Redash. Then, you can access with your browser with admin/admin.
Add Data Source of Impala
After clicking Database icon, you can add data sources.
This time, I set configurations as follows:
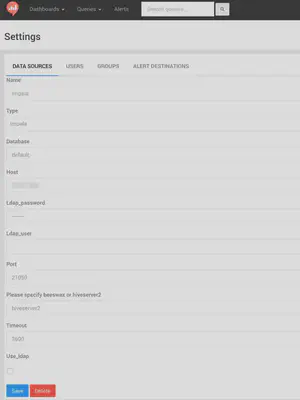
- Type: Impala
- Database: default
- Host: hostname of Impala daemon
- Ldap_password/user: (empty)
- Port: 21050 (default port)
- Please specify beeswax or hiveserver2: hiveserver2
- Timeout: 3600
- Use_ldap: (empty)
Now, you can select Impala as a data source.
Aki Ariga
Staff Software Engineer
Interested in Machine Learning, ML Ops, and Data driven business. If you like my blog post, I’m glad if you can buy me a tea 😉